A Unified Overview of AI-Driven Broadcast Technology
George Deac
capablanca.ai
2025-03-05
AI-Driven Broadcast Technology
Introduction
Over the past decade, AI and machine learning technologies have significantly impacted the media and entertainment industries. Radio broadcasting, however, often relies on human curators to plan shows, select music, and deliver the content. radioai.ro proposes an alternative: a fully automated, AI-powered radio station in which:
- Daily news and radio shows are produced in real-time by intelligent agents trained on large corpora of text.
- Playlist generation is driven by an embedding model that encodes mood, sentiment, BPM, and genre for each track, thus allowing seamless transitions between songs and catering to listener preferences.
This system draws on multiple cutting-edge techniques:
- Transformer-based text generation for producing show scripts and news bulletins (Section 1.3).
- Music embedding modeling trained to map each track into a high-dimensional latent space capturing fine-grained musical attributes (Section 1.4).
- Scheduling and orchestration algorithms that combine text content blocks (e.g., headlines, commentary) with music tracks according to real-time user feedback and context (Section 1.5).
Related Work
Natural Language Processing (NLP) has evolved from statistical methods to deep neural architectures such as Transformer-based models , which are now state-of-the-art for language understanding and generation. In parallel, music recommendation research has employed deep embeddings to capture timbre, genre, tempo, and emotional valence . Projects like Musicmap outline the historical and stylistic interrelations of musical genres, offering a foundational taxonomy for advanced embeddings.
Text Generation and Content Agents
News Feed Aggregation
Daily news feeds are collected via RSS and JSON APIs
from various publishers. Each item is parsed, tokenized, and filtered for
relevance. A weighting factor ![]() is assigned to each incoming
article
is assigned to each incoming
article ![]() based on:
based on:
![]()
where:
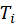 is
a topic-match score determined by the station’s editorial focus,
is
a topic-match score determined by the station’s editorial focus,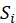 is
a sentiment score (derived via a fine-tuned BERT sentiment classifier ),
is
a sentiment score (derived via a fine-tuned BERT sentiment classifier ),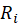 is
the recency or freshness factor.
is
the recency or freshness factor.
The top-ranked articles are summarized using a Transformer-based abstractive summarizer (e.g., T5 or BART). Final scripts are then passed to a text-to-speech subsystem for broadcast.
Show Scripting
For talk segments and editorials, the system uses a large language model (LLM) akin to GPT , fine-tuned on:
- Historical radio scripts and transcripts.
- Daily updated corpora focusing on current events, trends, and cultural references.
During generation, we employ a nucleus sampling
approach (top-![]() ) to maintain variety and avoid
repetitive content. The system also uses prompt chaining, in which
bullet-point outlines are generated first, then expanded into fully coherent
show scripts.
) to maintain variety and avoid
repetitive content. The system also uses prompt chaining, in which
bullet-point outlines are generated first, then expanded into fully coherent
show scripts.
Music Embedding Modeling
A cornerstone of radioai.ro is the music
recommendation engine, which learns embeddings from a labeled dataset of tracks
reflecting properties such as genre, BPM, mood, and sentiment.
Each track ![]() is embedded as a vector
is embedded as a vector ![]() .
.
Embedding Architecture
We define a multi-branch neural network that ingests several track metadata features:
- Spectral Features (e.g., Mel-frequency cepstral coefficients).
- Metadata: BPM, key, release year, high-level mood tags.
- Genre Taxonomy: A multi-hot vector indicating possible genres/subgenres.
Each branch transforms its input into a latent representation:
![]()
where ![]() are
feed-forward or convolutional sub-networks. These intermediate representations
are concatenated and passed through a final projection layer:
are
feed-forward or convolutional sub-networks. These intermediate representations
are concatenated and passed through a final projection layer:
![]()
Similarity and Ranking
To select a track that best fits the current radio
segment, we compute a similarity score ![]() using
cosine similarity:
using
cosine similarity:
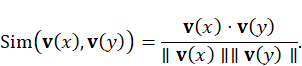
- If the broadcaster wants a mood shift to higher energy, we look for tracks with higher BPM embeddings and elevated arousal scores.
- If the context calls for a continuation of low-tempo relaxation, we focus on tracks with similar vibe embeddings.
Scheduling and Real-Time Adaptation
After generating potential news and commentary blocks (Section 1.3) and identifying suitable music tracks (Section 1.4), a scheduling agent orchestrates the final broadcast sequence. A hierarchical approach is used:
- Macro-Scheduling defines hour-level blocks (e.g., “Morning News,” “Lunch Break Show,” “Afternoon Drive”).
- Micro-Scheduling refines the exact content order based on real-time feedback such as like/dislike metrics, drop-off rates, and ongoing events.
The scheduling agent employs a dynamic programming
approach to maximize an objective function ![]() :
:

where:
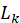 is
the predicted listener engagement for segment
is
the predicted listener engagement for segment 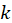 ,
,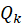 is
a quality measure reflecting synergy between music and spoken content,
is
a quality measure reflecting synergy between music and spoken content,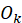 is
an “overlap penalty“ if transitions are abrupt,
is
an “overlap penalty“ if transitions are abrupt,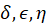 are
hyperparameters tuned on historical data.
are
hyperparameters tuned on historical data.
Implementation and System Architecture

Figure [1] (hypothetical) depicts the end-to-end architecture:
- Data Ingestion Layer pulls news feeds, user feedback, and track metadata.
- NLP Layer handles summarization, text generation, and TTS.
- Music Embedding Layer encodes new and existing tracks into a vector space.
- Scheduling & Orchestration merges textual and audio content into cohesive radio segments.
- Streaming & Analytics continuously monitors user interactions (e.g., skipping, rating), updating the preference model.
The system is containerized via Docker and orchestrated with Kubernetes for scalability. Real-time inference can be handled by GPU-accelerated servers, especially for Transformer-based text generation and large-scale embedding computations.
Conclusions
We have presented a comprehensive AI-driven system for automated radio broadcasting, demonstrating how modern Transformer models and advanced music embeddings can generate engaging talk segments and seamlessly curated playlists. This proof-of-concept fosters further research in AI-based content creation, music recommendation, and listener preference modeling.
Future work involves:
- Integrating multilingual support for global audiences,
- Refining the emotional alignment of transitions between news commentary and music,
- Expanding the framework to include visual or video segments for cross-platform content delivery.
Music Generation with Artificial Intelligence: A Detailed Overview
Abstract
Music generation via AI has emerged as a significant research area at the intersection of computational creativity, deep learning, and signal processing. Modern approaches leverage time-series modeling, variational autoencoders (VAEs), Transformer architectures, and generative adversarial networks (GANs) to synthesize both symbolic (MIDI-based) and raw audio music. This chapter offers a comprehensive overview of the landscape of AI-driven music generation, discussing key models, data representation choices, evaluation metrics, and future directions.
Introduction
Recent advances in machine learning, particularly deep learning, have greatly expanded the frontier of algorithmic composition and music generation. Historically, rule-based systems and Markov chains were popular for melodic or harmonic generation, but they often lacked creative expressiveness. Deep architectures, however, learn complex temporal and harmonic relationships directly from large musical corpora, leading to more coherent and stylistically rich compositions.
Key Goals of AI-Driven Music Generation:
- Melody Composition: Generating sequences that exhibit melodic coherence and structure.
- Harmonic Accompaniment: Creating chord progressions or orchestration parts aligned with a melodic line.
- Style Transfer: Transforming existing pieces into different styles or genres.
- End-to-End Audio Generation: Producing raw waveforms of music that closely match human composition in timbre and structure.
In the following sections, we explore data representation (symbolic vs. audio-based), model architectures (RNNs, Transformers, VAE-GAN hybrids), evaluation metrics, and future directions.
Data Representations for Music
Symbolic Representation
Symbolic representations like MIDI or piano roll data capture pitch, duration, velocity (dynamics), and timing information at a discrete resolution. This approach simplifies modeling, since the network deals with tokens or matrices rather than raw waveforms.
- MIDI Event Sequences: A musical piece is a sequence
of discrete events
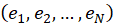 .
Each event can be a note-on, note-off, or control event.
.
Each event can be a note-on, note-off, or control event. - Piano Roll: A 2D matrix
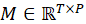 ,
where
,
where 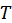 is the number of time steps
and
is the number of time steps
and 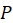 is the number of pitches.
is the number of pitches. 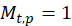 if
pitch
if
pitch 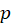 is active at time
is active at time 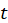 ,
else 0.
,
else 0.
Audio Representation
Generating raw audio requires modeling the waveform ![]() directly,
where
directly,
where ![]() spans
potentially hundreds of thousands of samples for even short musical excerpts.
This entails a high-dimensional generative problem. Popular approaches
include:
spans
potentially hundreds of thousands of samples for even short musical excerpts.
This entails a high-dimensional generative problem. Popular approaches
include:
- Waveform-based methods such as WaveNet .
- Spectrogram-based approaches, converting audio into time-frequency representations and then back to waveforms via inverse transformations (e.g., Griffin–Lim or a learned vocoder ).
Neural Network Architectures
Recurrent Neural Networks
Recurrent Neural Networks (RNNs) were among the first deep learning approaches for symbolic music generation.
- Vanilla RNN: A hidden state
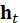 evolves
over time via:
evolves
over time via:
![]()
where
![]() is
a nonlinear function (e.g., a
is
a nonlinear function (e.g., a ![]() layer).
layer).
- LSTM : Uses gating mechanisms
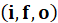 to
control information flow, mitigating vanishing gradients.
to
control information flow, mitigating vanishing gradients. - GRU : A streamlined variant of the LSTM with fewer parameters.
In practice, LSTMs proved particularly effective in learning long-term harmonic relationships for tasks like melody generation.
Transformer Models
Transformers revolutionized NLP by replacing recurrence with self-attention mechanisms:
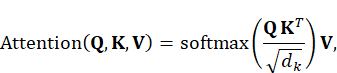
where ![]() are
the query, key, and value matrices, and
are
the query, key, and value matrices, and ![]() is
the dimension of the key vectors. In music generation, Transformers
(e.g., Music Transformer or Musenet by OpenAI) handle extended context spans,
capturing global structure (form, motifs) more effectively than typical RNNs.
is
the dimension of the key vectors. In music generation, Transformers
(e.g., Music Transformer or Musenet by OpenAI) handle extended context spans,
capturing global structure (form, motifs) more effectively than typical RNNs.
Variational Autoencoders (VAEs)
VAEs are generative models that learn a latent distribution for the data:
![]()
where:
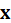 is
the input (music piece or snippet),
is
the input (music piece or snippet),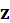 is
a latent variable,
is
a latent variable,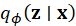 is
the encoder’s approximation of the posterior,
is
the encoder’s approximation of the posterior,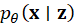 is
the decoder.
is
the decoder.
They optimize the Evidence Lower Bound (ELBO):
![]()
VAEs are often used for conditional music generation: for instance, generating new compositions similar to a reference piece by sampling from the learned latent space.
Generative Adversarial Networks (GANs)
GANs pit a generator ![]() against
a discriminator
against
a discriminator ![]() . The generator attempts to
produce realistic musical samples, while the discriminator learns to
distinguish real from fake. The objective:
. The generator attempts to
produce realistic musical samples, while the discriminator learns to
distinguish real from fake. The objective:
![]()
GANs have been used to produce short clips of audio or symbolic sequences, though training stability can be challenging. Hybrid architectures like MuseGAN combine symbolic representations with a multi-track generator to produce multi-instrument pieces.
Training Procedures
Dataset Preparation
Large, diverse corpora enhance robustness. Examples include the MAESTRO dataset for classical piano, the Lakh MIDI Dataset , or specialized jazz collections.
Loss Functions and Regularization
- Cross-Entropy Loss for token-based models:
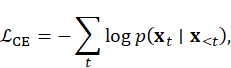
- Reconstruction Loss for VAEs (e.g., mean square error in a piano roll or cross-entropy for token-based).
- KL Divergence for VAE latent regularization.
- Adversarial Loss for GAN-based approaches.
Inference and Sampling
During generation, music models may use:
- Greedy decoding: picking the most likely next token or sample.
- Sampling: random draws from
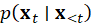 .
. - Beam search or top- (nucleus)
sampling to maintain diversity.
Evaluation Strategies
Objective Metrics
- Perplexity (PPL): Measures how well the model predicts the ground truth sequence.
- Chord/Harmony Metrics: Evaluations based on chord detection and progression coherence .
- Self-BLEU: Borrowed from text generation, measuring diversity by comparing generated pieces to each other.
Subjective Listening Tests
Music is inherently subjective. Researchers often conduct:
- Listening Studies: Presenting short generated clips vs. human-composed clips, asking participants to rate quality, coherence, and originality.
- Turing-test-like Evaluations: Listeners guess whether a sample was generated by a human or machine.
Musicological Analysis
For advanced research, domain experts (musicologists) analyze generated pieces for structural complexity, thematic development, and stylistic consistency.
Case Study: Hybrid VAE-Transformer for Symbolic Music
Suppose we want to fuse the representational power of a VAE with the long-range context handling of a Transformer. One might adopt the following pipeline:
- VAE Encoder: Encodes an entire sequence (e.g.,
a MIDI track) into a latent code .
- Conditioning: A Transformer-based decoder takes as
an additional context when generating the output tokens.
- Loss: Combined ELBO + cross-entropy on token prediction.
Model Equations:
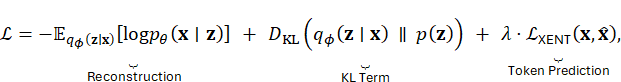
where ![]() is a hyperparameter controlling
the balance between VAE reconstruction and token-level cross-entropy. This
setup can produce diverse, stylistically coherent compositions that
capture both local structure (through token-level modeling) and global
variation (through latent codes).
is a hyperparameter controlling
the balance between VAE reconstruction and token-level cross-entropy. This
setup can produce diverse, stylistically coherent compositions that
capture both local structure (through token-level modeling) and global
variation (through latent codes).
Future Directions
- Multimodal Integration: Combining music generation with visual or textual cues (e.g., generating music from descriptive text prompts or images).
- Interactive Generation: Real-time co-creation tools where human users steer the AI’s output via feedback loops.
- Expressive Performance Modeling: Going beyond notes to capture articulation, dynamics, rubato, and other performance nuances.
- Ethical and Legal Considerations: As generated music approaches professional quality, questions arise about copyright, originality, and fair use of training datasets.
Conclusion
AI-driven music generation has advanced dramatically, moving from simple rule-based systems to deep neural architectures capable of capturing complex musical structure. Symbolic approaches (MIDI, piano rolls) remain highly effective for composition tasks, while audio-driven models produce increasingly realistic soundscapes. The field continues to grow, with promising results in style transfer, performance modeling, and interactive composition.
In summary, state-of-the-art models blend techniques like RNNs, Transformers, VAEs, and GANs, each offering unique strengths. Ongoing research seeks to further improve the creativity, expressiveness, and adaptability of AI-generated music, ushering in a new frontier of computational creativity for both academic and commercial applications.
References
A. van den Oord, S. Dieleman, H. Zen, K. Simonyan, et al. WaveNet: A Generative Model for Raw Audio. In SSW, 2016.
S. Yang, H. S. Choi, S. Kim, and K. Jung. MelGAN: Generative Adversarial Networks for Conditional Waveform Synthesis. In NeurIPS, 2019.
S. Hochreiter and J. Schmidhuber. Long Short-Term Memory. Neural Computation, 9(8), 1997.
K. Cho, B. van Merrienboer, C. Gulcehre, D. Bahdanau, et al. Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation. In EMNLP, 2014.
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, et al. Attention Is All You Need. In NIPS, 2017.
C.-Z. A. Huang, A. Vaswani, J. Uszkoreit, et al. Music Transformer: Generating Music with Long-Term Structure. In ICLR, 2019.
D. P. Kingma and M. Welling. Auto-Encoding Variational Bayes. In ICLR, 2014.
I. Goodfellow, J. Pouget-Abadie, M. Mirza, et al. Generative Adversarial Nets. In NIPS, 2014.
H.-W. Dong, W.-Y. Hsiao, L.-C. Yang, and Y.-H. Yang. MuseGAN: Multi-track Sequential Generative Adversarial Networks for Symbolic Music Generation and Accompaniment. In AAAI, 2018.
C. Hawthorne, A. Stasyuk, A. Roberts, et al. Enabling Factorized Piano Music Modeling and Generation with the MAESTRO Dataset. In ICLR, 2019.
C. Raffel. Learning-based Methods for Comparing Sequences, with Applications to Audio-to-MIDI Alignment and Matching. PhD Thesis, Columbia University, 2016.
A. Holtzman, J. Buys, L. Du, M. Forbes, and Y. Choi. The Curious Case of Neural Text Degeneration. In ICLR, 2020.
A. Vaswani, N. Shazeer, N. Parmar, et al. Attention Is All You Need. Advances in Neural Information Processing Systems (NeurIPS), 2017.
A. van den Oord, S. Dieleman, & B. Schrauwen. Deep content-based music recommendation. Proceedings of the Neural Information Processing Systems (NIPS), 2013.
Musicmap: A Genealogy of Modern Popular Music. Retrieved from https://musicmap.info.
J. Devlin, M.-W. Chang, K. Lee, & K. Toutanova. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. Proceedings of NAACL-HLT, 2019.